In the first release of Nautobot all of the Jobs were Atomic by default. This was from the previous focus of the legacy source application that assumed that scripts/reports would only be run on the data locally, so by that nature, the jobs should be atomic. As more and more Jobs started to interact with other systems, it became apparent that there needed to be a control mechanism provided (as I understand). So the introduction of a context manager and decorator was brought to the table to provide the same previous functionality while changing of the default behavior in Nautobot 2.x+.
In this post, we'll dive into WAN design and address a common question that I was provided with in the 2000s: "My home internet costs only $35 per month. Why do we spend $xxx per month per circuit?"
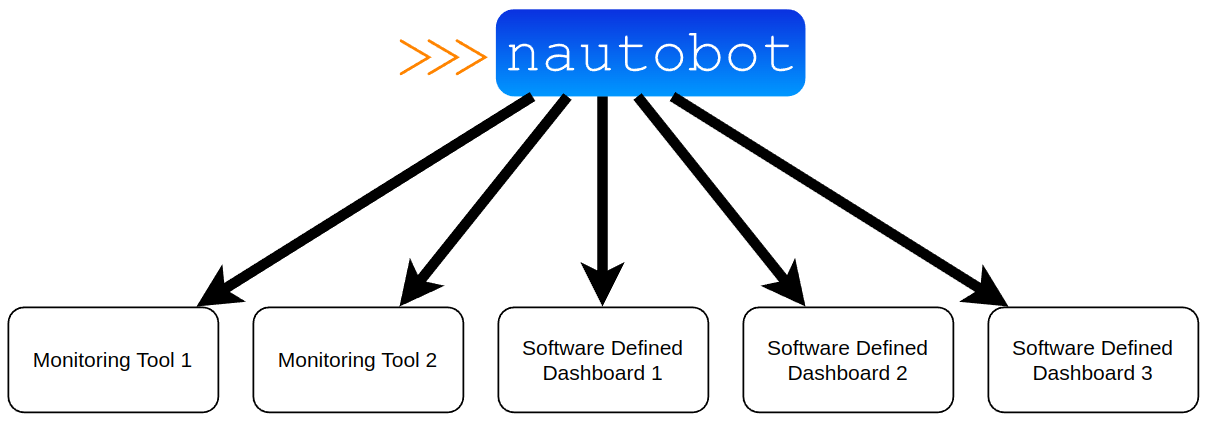
One of my favorite features of Nautobot that may not be well known is the capability to put a button on pages that take you to other locations. This can be helpful when lining up the source of truth as that first place that you go, the idea of adding custom links will just help to enforce that as the first place to go. When you look at the idea of a source of truth to help feed other systems, you start to see the topology like below.
Just recently released at the beginning of 2024 is a project that I am super excited to see in the open source by Network to Code. This is the Nautobot App cookiecutter template. This may already be the biggest thing to become available for Network Automation in 2024. I know, its fresh at this point in the year, but this is something that is going to make getting started with your own Nautobot Application so much quicker.
The year of 2023 I think may have had some of the biggest leaps in the Network Automation capabilities that are being delivered by some of the best in the business. With Nautobot's Golden Config App adding the ability to complete configuration remediation and Ansible release Event Driven Ansible, there are a couple of powerful tools to help you with your Network Automation. And all with a great new conference addition specific to Network Automation.
In my home environment I am leveraging Nautobot as my source of truth. This is for the network, which is probably not all that interesting in my home environment, and my virtual machines. Why am I tracking my virtual machines in Nautobot? Simple, to help automate them. I think that this is a clever methodology to help use tags and to get automation working within the environment. This same type of thing may be applicable to your network environment as well.
Within Nautobot there are many ways to be able to get the Nautobot environment running. Environment variables are used quite a bit in the Docker environment following best practice principles set forth in the 12 Factor App. The use of environment variables is helpful for working through the various stages of an application to production. The installation instructions leverage a single environment variable NAUTOBOT_ROOT and that is set in the SystemD files shown below.
One observation lately is that Python is moving along quickly with new versions and new EOLs. Along with needing to make these updates, the applications that Python uses will also need to be moving along. Nautobot is my favorite, and in my opinion the best SOT platform available in the open source ecosystem today. So let's dive into the updating of the Python version.
For this post, I've created a new Rocky 8 Virtual Machine to be the host. See the note below for the reasoning. This will start off with a Nautobot install from the Nautobot docs. I won't dive into all of that, assume that is the starting point with a fresh Nautobot application.
Here I'm going to dive into what I'm planning to build out for my next desktop here in 2023. Prime Day is nearly upon us, and I'm anticipating (but do not know for sure) that prices on some of the gear that I'm looking for will be available at a good price. I'm also looking to build out a bigger system in order to run some intense VMs up coming.
My goals:
- Build a system that will last for 3-4 years at a minimum
- Max out the RAM, that is my most limiting factor in my environments
- Give Linux a try as the desktop OS, still a bit of debate in this, considering options:
- Debian 12
- POP OS
- Linux Mint
One of Nautobot's primary functions is to serve as an IPAM solution. Within that realm, the application needs to provide a method to get at IP address data for a device, quickly and easily. In this post I will review three prominent methods to get an IP address from Nautobot. It will demonstrate getting the address via:
In this post I'm going to dive into a bit more on the Nautobot custom validators. This is a powerful validation tool that will allow for you to write your own validation capability, including in this demonstration on how to complete a validation against a remote API endpoint. The custom validators are a part of the Nautobot App extension capability. This allows for custom code to be written to validate data upon the clean() method being called, which is used in the majority of API calls and form inputs of Nautobot.
With Nautobot, one of the things that came up was how to work with secrets. Nautobot itself is not the place to maintain secrets, as it is not a vault. There may be some good cryptographic libraries out to handle this, but by its nature, that is not the intent. So Nautobot has written methods to be able to retrieve secrets from proper vault sources and be able to leverage them. These can be tricky to get set up however. I had struggled for a while myself. So now that I have it working, I thought it would be a good time to have a quick personal blog about it.
Today I was working to demonstrate how to get started with Nautobot Jobs within the Jobs root of Nautobot. This is not a pattern that I develop often, as I am typically developing Jobs within a plugin as my development standard. More to come on that later. During this case, the ask was to build a Job that would connect to a network device. I had a few troubles that I didn't want to have to work through on a call that had limited time and that was a screen share. So I am taking to working on this via a blog post to share, and hopefully will be helpful for others as well.
One of the great things about building an enterprise system, is being able to get systems to work cohesively amongst themselves to bring a complete solution. One of the workflows that is often required in a static IP address environment is the need to provide static IP addresses to hosts on a network segment. When using an IPAM (IP Address Management) solution such as Nautobot, the APIs and SDKs/modules made available for use in automation workflows is paramount to having the cohesion to make a seamless IT system.
In this post I will be diving into the use of Nautobot as the IPAM. Using Ansible and the Nautobot modules, I will then show how you can get the next available IP address and assign it for use to the next VM. There will likely need to be some minor tweaks for use in your system.
One of the features that I find myself using periodically that I think is underrated as far as using GraphQL is its ability to alias return keys in the response. This can be extremely helpful for developers writing applications, as it allows them to have the API response with the keys they are looking for. I have found this feature particularly useful when working on applications like Meraki and Nautobot together. In Nautobot a place is typically defined as the key site. In the Meraki world this is commonly set up as a network. Without GraphQL's alias feature, the developer would need to translate this data over.
Let's explore two scenarios where a developer might choose to alias the response from GraphQL:
Quick translation between systems
Response from multiple queries
I will demonstrate the capabilities of these scenarios using the Nautobot demo instance at https://demo.nautobot.com. For each of these, make sure that you have logged in already before going to the GraphiQL page.
All of the work through the modules thus far in the series have brought us to what we all want to see. How to get or update device information inside of Nautobot. Adding of sites, device types, device roles are required to get us to this point. Now you can see how to add a device to Nautobot using the networktocode.nautobot.device module.
There are many optional parameters for the module specifically. I encourage you to take a look at the module documentation (linked below) in order to get a good sense of all of the options available. The required parameters for a device that is present are:
device_role
device_type
name
site
status
An important caveat for me is that this is something that should be done with rarity. Only when truly adding a device to Nautobot, in a programmatic way this should be used. I do not advocate for running this module constantly based on your devices. The idea is to get Nautobot to be your source of truth about devices, not to have devices be the source of truth and updating Nautobot.
So where do I see this being run? I do absolutely see it being a part of a pipeline or a service portal. The idea being that the service portal has a request for a new site to be turned up. That in turn kicks off an Ansible Playbook that will make the necessary updates to Nautobot, and is done in a consistent manor.
A device type is the next piece in the Nautobot Device onboarding requirements. The device type corresponds to the model number of the hardware (or virtual machine). This is where you are able to template out devices during their creation. So if you have a console port on a device type, that console port will be created when you create the device. However, there is NOT a relationship built between the device type and the device. If the device type gets updated after the device is created, the device itself is not updated.
A device role is aptly named, the role of the device. This is likely to be something that is meaningful to your organization and could change. For example you may have the 3 tier system of Core, Distribution, and Access layer environments. These are just fine. So you would want to have the roles there to reflect this reality. You may have leaf-spine environments, there are two more roles. And in my past I have also had roles that would indicate that there are dedicated DMZ, WAN edge, Internet edge devices. So this is the place to set this.
Adding your manufacturers via code is the easy way to get started with your Nautobot devices. Immediately after adding Sites, the next thing to get going when using Nautobot as your Source of Truth is to add in Manufacturers. These are just that, who makes the gear that you use. For this demonstration you will see adding just a few manufacturers. I'm not necessarily picking on any vendors and who should or shouldn't be here. It is just what my background brings.
Platforms are an optional item when adding devices into Nautobot. The platform is the OS that you are going to be using. Most often this is used to help identify which driver your automation platform is going to be using. Specifically the slug of the platform is what needs to match. So in the terms of Ansible (since we are using Ansible to populate Nautobot), you will want to set Cisco IOS devices to ios. By having the slug match the automation platform name you have that information in your inventory. For these reasons I strongly recommend setting the Platform for devices.